Technische Datenorganisation
&
Programmieren
Error! Reference source not found.
Unter Kopplung versteht man den Grad der Kommunikation zweier Unterprogramme untereinander. Wegen der einfacheren Wartbarkeit sollte die Kopplung möglichst gering gehalten werden. Man unterscheidet verschiedene Arten der Kopplung:
Datenkopplung
Steuerungskopplung
Globale Kopplung
Inhaltskopplung
Die Datenkopplung ist ein Maß für die Anzahl der Übergaben von Variablen oder Werten in ein Unterprogramm.
Bsp.:
v = up2(c, r, x, 7, y, 23, a, b)
Darunter versteht man die Übergabe von Werten, die versteckte Befehle darstellen. Bsp.:
Dateibearbeitung('h:xesas.mdb', Aktionscode)
Aktionscode: 1 Öffnen
2 Schließen
3 Löschen
Das ist die Kopplung mittels globalen Variablen. Nachteile:
Welches Unterprogramm hat den Wert der Variablen geändert
Wenn die Bezeichnung einer Variablen geändert wird, muß sie in allen Unterprogrammen geändert werden.
Hier ändert up1 den Programmcode von up2. Diese Art der Kopplung macht die Wartung nahezu unmöglich. Sie ist in höheren Programmiersprachen nicht möglich, sondern nur im Assemblercode durchführbar.
Unter Kohäsion versteht man des Verhältnis eines Unterprogrammes zu seiner Aufgabe. Kohäsion ist, mit Ausnahme der funktionalen Kohäsion, nicht erwünscht. Ein guter Entwurf beinhaltet eine geringe Kopplung und eine hohe funktionale Kohäsion. Man unterscheidet:
Zufallskohäsion
Zeitliche Kohäsion
Prozedurale Kohäsion
Logische Kohäsion
Funktionale Kohäsion
Sequentielle Kohäsion
Diese ist gegeben, wenn innerhalb eines Unterprogramms Aufgaben erledigt werden, die inhaltlich nichts miteinander zu tun haben (Datei bearbeiten, Fibonacci Zahlen ausrechnen, Text ausgeben in einem Unterprogramm).
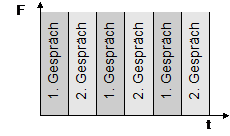
Ein Unterprogramm enthält Aufgaben die zu selben Zeitpunkt innerhalb des Programmablaufes durchgeführt werden (Bsp.: Beim schließen einer Datei, beim öffnen eines Wertpapiergeschäftes).
Dieser Fall liegt vor, wenn zwei Unterprogramme zusammengefaßt werden, die die selbe Steuerungsstruktur aufweisen (Bsp.: 2 Hunderterschleifen).
Dies ist das Gegenstück zur Steuerungskopplung.
Diese liegt vor wenn die beiden Unterprogramme auf die selben Daten zugreifen.
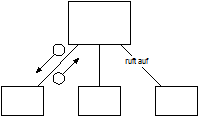
Diese ist erwünscht, da hier ein Unterprogramm genau eine Aufgabe hat. Welchen Umfang diese Aufgabe hat, hängt von der funktionalen Dekomposition ab.
|
Funktionsdekomposition |
Structure Chart |
|
|
|
|
Aufgabe |
Lösung |
![]()
Die drei wichtigsten Regeln zum Testen lauten:
Man sollte nie die eigenen Programme testen
Immer die besten Programmierer sollten die Tests durchführen
Das Ziel sollte das Finden von Fehlern, und nicht das Beweisen des Funktionierens des Programmes sein.
Man unterscheidet den Blackboxtest und den Whiteboxtest.
Dieser wird auf der Basis des Programmcodes durchgeführt. Man sucht im Programmcode nach typischen Fehlern wie:
of one error
dangling pointer
division by zero
unreachable Code
Endlosschleife
falsche Parameterübergabe
Ideal wäre es, alle Pfade, die durch if-Klauseln oder Schleifen entstehen, durchzugehen, was aber bei Tausenden Schleifendurchläufen nicht möglich ist. Man sucht daher nach der besten Möglichkeit alle Fehler zu finden, und gleichzeitig nur die allernötigsten Pfade durchzugehen.
Dieser wird auf Basis der Spezifikation durchgeführt. Mittels geeigneter Testdaten versucht man alle Aktionen durchzuführen. Die Testdaten sollten gleichzeitig mit der Spezifikation erstellt werden. Dazu verwendet man Aquivalenzklassen. Die Testmenge wird in Teilmengen zerlegt, deren Werte ähnlich sind. Aus jeder Aquivalenzklasse soll ein Testfall entnommen werden (Bsp.: Programm zur Dreieckseinteilung).
Dies sind Maßzahlen, über die mittels Formeln und Tabellen die Fehleranzahl eines Programmes geschätzt werden kann. Solche Maßzahlen sind z.B. die Anzahl der Zeilen, der if-Klauseln, der Schleifen, usw.
Es werden bewußt Fehler eingebaut, und dann im Programm nach allen Fehlern gesucht. Aus dem Vergleich der gefundenen und der versteckten Fehlern kann Aufschluß über die Gesamtfehlerzahl gewonnen werden.
Codeinspektion: Programmierer treffen sich, und sprechen den Code Zeile für Zeile durch
Walkthrough: Rollenspiel, wo jeder einen Programmteil spielt
Peer Rating: 6 bis 20 Programmierer. Tauschen Programme aus, und kontrollieren sie gegenseitig auf Verständlichkeit, Wartbarkeit und Dokumentation
Review: Standards werden vom SQS - Menschen und dem Programmierer durchgenommen.
Das Ziel des Information Engineering ist es, das mehrfache Vorhandensein von Daten, oder Funktionen zu verhindern. Bsp.: Innerhalb eines Betriebes sind die gleichen Daten in verschiedenen Datenbanken gespeichert, und Funktionen wie das Suchen oder Sortieren von Mitarbeitern sind in jedem Programm extra implementiert.
Die Lösung dafür ist eine einheitliche Datenbank für das ganze Unternehmen. Dies beinhaltet:
UDM unternehmensweites Datenmodell
UFM unternehmensweites Funktionsmodell
Das UDM spielt dabei eine bedeutendere Rolle, weil sich Daten langsamer ändern als Funktionen. Z.B.:
Der Unterschied zwischen dem Information Engineering und dem Software Engineering ist, daß das Pflichtenheft des SE durch das Planning ersetzt wird. Nach James Martin unterteilt sich das Information Engineering in folgende Teilgebiete:
Planning
Analysis
Design
Constructing
Das Planning sollte von vier Mitarbeitern in einem halben Jahr durchgeführt werden können. Ist das nicht möglich, ist es zu fein durchgeführt worden. Das Ziel sollte sein, sich einen Grobüberblick über das Unternehmen zu schaffen.
Das UDM wird vorerst mit entity clusters (subject area) erstellt. Diese werden nach dem Planning in feinere ERDs zerlegt. Bsp.: Der Konzern SHELL hat die entity clusters Fahrzeug, Mitarbeiter, Kunde, Organisation usw.
Für das UFM wird eine grobe Funktionsdekomposition erstellt. Im Allgemeinen wird sie soweit durchgeführt, bis keine Funktionen, sondern Prozesse vorhanden sind. Prozesse haben im Gegensatz zu Funktionen einen Anfang und ein Ende.
Es wird ein Baum aufgebaut, indem Ziele in ihre einzelnen untergeordneten Ziele zerlegt werden:
Andere Ziele sind:
monetär
humanitär
marktorientiert
produktorientiert
ökologisch
Kritische Erfolgsfaktoren (critical success factors) sind vom Betrieb unbeeinflußbare, äußere Faktoren, die auf den Betriebserfolg Wirkung ausüben (z.B.: Dollarkurs, Marktsituation, ):
Positive kritische Erfolgsfaktoren (facilitators) erleichtern das Erreichen des Betriebszieles
Negative kritische Erfolgsfaktoren (inhibitors) wirken den Betriebszielen entgegen.
Diese werden gebildet, um Verbindungen (Assoziationen) zwischen den vier bekannten Dokumenten (UDM, UFM, Organigramm, Zielfestlegung) herzustellen (CDUR Matrix). In unserem Beispiel ist die Verbindung zwischen Organigramm und Zielfestlegung dargestellt:
|
Stellen |
Ziel 1 |
Ziel 2 |
Ziel 3 |
Ziel 4 |
Ziel 5 |
|
Direktor |
X |
|
X |
|
|
|
Abteilungsvorstand techn. |
|
X |
|
|
|
|
Abteilungsvorstand kaufm. |
|
|
|
|
|
|
Werkstättenleiter |
|
X |
|
X |
|
In diesem Fall würde eine Information Engineering - Software die Fehlermeldungen
Stellen ohne Ziele
Ziel 5 wird nicht verfolgt
anzeigen.
Sie stellt die Verbindung zwischen den Stellen und den Funktionen dar. In den Zellen werden die Beziehungsarten eingetragen:
Responsibility (Verantwortung)
Authority (Autorität, Vollmacht)
Expertise (Fachwissen)
Work (Arbeit [in])
Bsp. zur RAEW Matrix für unsere Schule:
|
Stelle |
Schülerverwaltung |
Unterricht |
Finanzentscheidung |
|
Direktor |
R |
RE |
|
|
Abteilungsvorstand techn. |
REA |
EA |
W |
|
Abteilungsvorstand kaufm. |
|
W |
|
|
Werkstättenleiter |
|
EW |
EW |

Nach dem Planning stellt sich das Problem, wie das UDM und das UFM zerlegt werden soll. Mit der Affinitätsanalyse wird nun das Gesamtprojekt in verschiedene Einzelprojekte zerlegt.
a(E = Anzahl der Prozesse, die die Tabelle E benützen
a(E , E = Anzahl der Prozesse, die sowohl E und E benützen
Affinität von E1 nach E2:
![]()
affin(E , E ) = 0 Prozesse gehören in verschiedene Unterprojekte
affin(E , E ) = 1 Prozesse gehören in das selbe Unterprojekt
Bsp.:
|
E |
E |
|
|
E |
E |
|
|
E |
E |
|
|
E |
E |
|
Error! Reference source not found. E und E werden zu einem E zusammengefaßt, und eine neue Affinitätsanalyse wird durchgeführt. Affinitäten für E werden mittels gewichtetem Durchschnitt berechnet:
![]()
In der Software erfolgt die Einstellung der minimalen Affinität zur Zusammenfassung zweier Gruppen folgendermaßen:
Minimum Affinity to merge two groups: (z.B.: 0,7)
Nach der Affinitätsanalyse erhält man Projekte. Will man eine bestimmte Anzahl von Projekten, muß man den Faktor danach anpassen. Dann kann man entscheiden, mit welchem Projekt man beginnen soll. Diese Entscheidung kann aufgrund der Projektgröße oder der Wichtigkeit getroffen werden.
In der Analyse erstellt man das Fein - ERD und eine feinere funktionale Dekomposition. Weiters werden Interaktionsanalysen durchgeführt. Die Analysis läßt sich also folgendermaßen unterteilen:
Da die Planning gröbere Daten- und Funktionsstrukturen behandelt, ergibt sich folgende Gliederung für die feine Analysis:
|
Behandelte Objekte |
Planning |
Analysis |
|
Daten |
subject areas |
entity types |
|
Funktionen |
Funktionen |
Prozesse |
Aus Befragungen und der Durchsicht von bereits existierenden Formularen erhält man Datenelemente, die später zu Attributen werden. Im Bubblechart werden alle Datenelemente aufgeschrieben und miteinander verbunden. Dies geschieht indem man die Abhängigkeiten einträgt:
Aus diesem Diagramm entfernt man transitive Abhängigkeiten. Z.B.:
Hinzugefügt wird Intersection Data. z.B.:
Aus dem Bubblechart ergibt sich eine voll normalisierte Datenbank:
|
Bubblechart |
Tabelle |
|
|
E (x, y, z) |
|
|
E (x, y) |
|
|
E1 (x, z) und E2 (x, y) |
Danach kann man die Datenbank noch denormalisieren, und zwar dann, wenn oft auftretende Joins viel Zeit verbrauchen würden:
|
normalisiert |
denormalisiert |
|
A (Mitarbeiter#, Abteilungs#) B (Abteilungs#, Abteilungsleiter) |
A (Mitarbeiter#, Abteilungs#, Abteilungsleiter) |
Hier kann denormalisiert werden, wenn zu einem Mitarbeiter oft der Abteilungsleiter gesucht werden muß, weil jedesmal ein Join erforderlich wäre.
Der Funktionsbaum gibt keine Auskunft über die Reihenfolge, in der die Prozesse ausgeführt werden. Elementare Prozesse sind funktional kohesiv. Im Prozeßabhängigkeitsdiagramm werden nun die Beziehungen zwischen den Prozessen dargestellt.
|
Beziehung |
Darstellung in IEF |
Beschreibung |
|
A enables B |
A Error! Reference source not found. B |
B kann erst laufen, wenn A beendet ist |
|
X disables Y |
|
Ist X abgelaufen kann Y nicht mehr laufen |
|
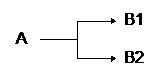
|
B1 und B2 können erst laufen, wenn A beendet ist |
|
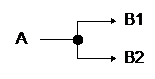
|
B1 und B2 schließen einander aus |
Daraus kann auch ermittelt werden, welche Prozesse gleichzeitig ablaufen. Das hat besondere Bedeutung bei der Programmierung auf parallelen Rechnersystemen.
Prozesse werden meistens nicht durch andere Prozesse, sondern durch Ereignisse hervorgerufen. Man unterscheidet dabei in externe und zeitliche Ereignisse. Die externen sind vom Programm nicht beeinflußbar, wie z.B. Benutzereingaben. Zeitliche Ereignisse ergeben sich bei bestimmten Zeitpunkten, ein Beispiel hierfür ist das Versetzen von Schülern in den nächsten Jahrgang.
Bei der Interaktionsanalyse werden die Zusammenhänge zwischen der Daten- und der Prozeßseite dargestellt. Dazu gibt es folgende Hilfsmittel:

Bei der ELCA betrachtet man die Objekte, und welche Zustände sie während des Programmablaufes einnehmen können. Weiters ermittelt man die Prozesse, die sie von einem in den anderen Zustand versetzen. Z.B.: Schüler
![]()
Aus den Betriebssystemen sind bereits die vier Prozeßzustände bekannt:
z.B.: Mietwagen
Ein weiteres Beispiel wäre eine OSI Schicht 2 Protokollinstanz, die die Zustände
Sent & Waiting
Ack receded
Ack received
einnehmen kann.
Bei der EVA betrachtet man die Prozesse, mit den Daten, die er erhält, abfragt aber auch liefert:
Bsp. Bestellannahme:
Der Kunde ruft an, und gibt seine Kunden#, die bestellten Produkte und deren Menge an. Ist die Kunden# vorhanden, wird die Bestellung erstellt. Sie beinhaltet die Bestell#, den Gesamtbetrag, und das Datum. Als erstes wird das dafür notwendige ERD erstellt:
Daraus folgen die verschieden Datenflüsse :
Import View K#
(P#, Stk)*
Mit einem Stern werden diejenigen Attribute versehen, die mehrmals eingegeben werden müssen. In unserem Beispiel kann man ja pro Bestellung mehrere Bestellposten angeben.
Darstellung in IEF:
|
Gruppe |
Viewname |
Entity |
Attribute |
|
|
Import |
|
|
|
|
|
Kunde |
|
|
|
|
|
K# |
|
Bestellte Posten |
|
|
|
|
|
|
Bestellposten |
|
|
|
|
|
Stk |
|
|
|
Produkt |
|
|
|
|
|
P# |
|
End Bestellte Posten |
|
|
|
Export View B#
GesError! Reference source not found.
Datum
Entity Action View C: Bestellung
C: Bestellposten *
R: Kunde
R: Produkt
Daraus kann man das Prozeß - Logikdiagramm erstellen, daß aber auch noch keine Auskunft über die Reihenfolge der Ausführung angibt:
A Associate (C)
D Dissociate (D)
T Transfer (U)
Wenn dieses Diagramm erstellt ist, kann die Information Engineering - Software endlich den Programmcode erstellen. In Bezug auf Dr. Dipl. Ing. Mag. Hasitschka endet bereits hier die Analysis, und beginnt das Design. James Martin zieht diese Grenze erst nach dem Action Diagram
|
Action Diagram |
Beschreibung |
|
|
Anweisungen |
|
|
Schleife |
|
|
Verzweigung (If - Klausel) |
|
|
Verzweigung (CASE Anweisung) |
|
|
Schleife verlassen, nächster Schleifendurchlauf |
|
|
gleichzeitige Anweisungen (für Parallelrechner) |
Bsp. Bestellannahme:

Information Engineering - Programme können noch keine Masken erstellen. Die Masken müssen daher vom Entwickler erstellt werden. Formulare die Eventhandler enthält nennt man "Procedure Step" oder Dialog. Man kann mehrere Prozesse in einem Dialog zusammenfassen (Anlegen, Löschen, Andern). Es können aber auch Prozesse auf mehrere Masken aufgeteilt werden, z.B. aus Platzgründen am Bildschirm.
Hier werden die möglichen Pfade durch die Dialoge festgelegt. Dazu verwendet IEF zwei Arten von Verbindungen:
![]() link flow
(Wechsel in beide Richtungen möglich)
link flow
(Wechsel in beide Richtungen möglich)
![]() transfer flow
(Wechsel nur in eine Richtung möglich)
transfer flow
(Wechsel nur in eine Richtung möglich)
Im Beispiel besteht der Listengenerator Schüler aus zwei Masken, wobei man in die zweite nur über die erste gelangen kann, die Verwaltung der medizinischen Daten ist aber von beiden Dialogen unabhängig:

Bsp. Bestellannahme: Wechsel zur Fehlermeldung, wenn Kunden# nicht gefunden (link flow
EXITSTATE IS Kunde_Not_Found (Maskenwechsel)
FLOWS ON Kunde_Not_Found
RETURNS ON
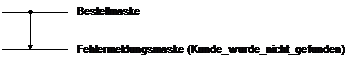
PROCEDURE STEP
COMMAND (was ist mit Daten zu tun)
if COMMAND = . . .
Nach dem Design sind alle Informationen vorhanden, um das Programm erstellen zu können.
Im Constructing erfolgt die Umsetzung in den Programmcode. Dazu kann eine Plattform eingegeben werden (z.B.: Oracle). Eine Nachbearbeitung kann aber nur schwer erfolgen, da die Casetools nicht dafür ausgelegt sind (keine sprechenden Variablen usw.). Ein weiterer Nachteil der meisten Casetools ist, daß der Programmcode meisten nicht sehr effizient programmiert ist.
Beim Aufbau von Netzwerken ergeben sich verschiedene Probleme. Angefangen von den Spannungen für 0 und 1 über die Übertragungsart von Paketen bis hin zu der Zeichendar-stellung (ANSI, ASCII, Einser- oder Zweierkomplement) muß alles geregelt werden. OSI hat alle Probleme in sieben Schichten eingeteilt, und für sie Lösungen vorgeschlagen. Die Regeln, die die Zusammenarbeit zwischen dem Sender und dem Empfänger ermöglichen, nennt man Protokoll (protocol). OSI schlägt aber für ein und das selbe Problem verschiedene Lösungen vor. Daher stehen im ISO - OSI - 7 Schichtmodell verschiedene Protokolle.
Damit nicht für jedes Netzwerk ein Protokoll programmiert werden muß, gibt es bereits die Schichten 1 - 3 fertig in Chips zu kaufen.
Definition laut Hansen:
Das Referenzmodell beschreibt ein allgemeines abstraktes Modell für die Kommunikation zwischen Datenstationen, d.h. es werden nur die wichtigsten Eigenschaften des Außenverhaltens festgelegt. Die Arbeitsgemeinschaft OSI (Open System Interconnection) der ISO (International Standardisation Organisation) hat diese Richtlinien entwickelt.
Bsp.: Lehner überträgt Daten zu Edlauer
|
L zu E: 9V, 2V, 7V, 5V, 11V |
Bedeutung unklar Error! Reference source not found. Ausmachung 8V = 1, 3V = 0 |
|
E empfängt: 3V, 8V, 8V, 3V, 8V (01101) L sendete: 0110011101111110010010101100 |
Zeitintervalle verschieden Error! Reference source not found. Festlegung 10 Werte / sec =10 BAUD 1 BAUD = 1 Wert / Takt um mehr Bit übertragen zu können wird folgende Vereinbarung getroffen 3V = 00 4V = 01 6V = 10 9V = 11 |
|
Jetzt kann korrekt übertragen werden: L zu E: 464494998436694 |
weiterhin 10 BAUD, es werden jetzt aber 20 Bit / sec übertragen |
Shannon und Nyquist haben Berechnungsformeln für die Kanalkapazität (Bit/sec) erstellt = Bandbreite. Unter Bandbreite wird aber auch das Intervall verstanden, das übertragen werden kann. Bsp.: Telefon; die Sprache kann nur zwischen 300 Hz und 3600 Hz übertragen werden. Als Faustregel kann man sagen, daß 1 Hz Bandbreite 2 Bit ergeben.
Bei der analogen Datenübertragung werden Sinusschwingungen übertragen. Die Arten der Übertragung sind:
|
Modulationsart |
|
|
|
Amplituden Modulation - AM lauter - leiser |
|
|
|
Frequenzmodulation - FM höher - tiefer |
|
|
|
Phasenmodulation - PM nicht wahrnehmbar |
|
|
Quadratur Amplituden Methode (QAM):
Die Winkel stellen die Phasenverschiebung, die Kreise die Amplituden dar. Zu beachten ist, daß die letzte Stelle des äußeren Kreises immer eine 1, im inneren eine 0, ist. Hier sind 3 Bit/Takt übertragbar.
Bei der digitalen Datenübertragung werden nur Nullen und Einsen übertragen. Der Vorteil der digitalen Übertragung ist, daß ein gestörtes Signal regeneriert werden kann, bei der analogen Übertragung bleibt die Störung.
|
Übertragungsart |
gesendet |
empfangen |
|
analog |
|
|
|
digital |
|
|
Bei der synchronen Datenübertragung verfügen sowohl der Empfänger als auch der Sender über einen Zeitgeber, der ständig läuft. Das Problem, das dabei entsteht ist, daß keine Uhr genau synchron zu einer anderen läuft:
Wegen der unterschiedlich laufenden Zeitgebern werden anstatt der gesendeten 43 nur 42 Nullen empfangen. Dieses Problem kann nur entstehen, wenn lange Ketten von gleichen Zeichen übertragen werden. Lösungen für dieses Problem sind:
Bit - Stuffing:
Beim Bit-Stuffing wird z.B. nach fünf gleichen Zeichen eine 1 angehängt. Diese muß nach der Übertragung vom Empfänger entfernt werden.
|
Daten |
Übertragung |
|
|
|
Return To Zero (RTZ):
Hier wird innerhalb eines Taktes nach dem Signal auf den Nullwert zurückgegangen:
Manchester Coding:
Hier werden die Zeichen folgendermaßen dargestellt:
Bei der asynchronen Datenübertragung überträgt der Sender, vor den eigentlichen Daten, Startbits (meistens 2) und oft auch nach der Übertragung Stopbits. Der Vorteil liegt darin, daß die beiden Zeitgeber nicht dauernd synchron laufen und daher ungenau werden, sondern nur während der Datenübertragung arbeiten. Der Nachteil ist die Bitverschwendung die durch die Start- und die Stopbits entsteht.
1. Definition:
Basisband ist jeder Kanal, der zu schmal ist, um ein Fernsehbild zu übertragen (5 Mbit/sec). Z.B.: Telefon
Beispiele für Breitband sind: Satelliten, Glasfaser- oder Koaxialkabel
2. Definition:
|
Basisband |
Breitband |
|
Time Division Multiplexing (TDM) |
Frequency Division Multiplexing (FDM) |
|
|
|
Vorteile:
billig
leicht zu verlegen
leicht erhältlich
leicht zu Konfektionieren (Verbindungsstücke anbringen)
unempfindlich
Nachteile:
nicht störungs- und abhörsicher
niedrige Kapazität (kbit/sec)
Vorteile:
höhere Kapazität (hundert Mbit/sec)
abhörsicher
Nachteile:
teuer
schwer zu konfektionieren
Arten der Übertragung:
multimode: mehrere Frequenzen (weißes Licht)
single- oder monomode: eine Frequenz (farbiges Licht)
Vorteile:
abhörsicher
störungssicher
hohe Kapazität (hundert Mbit/sec): 600 Mbit/sec entsprechen ca. 150 Fernsehkanälen und 150.000 Telefonleitungen.
Arten der Übertragung:
direkt zum Empfänger
über geostationären Satelliten in 36.000 Metern Höhe.
Nachteile:
nicht abhörsicher
Verzögerung über Satelliten
Ein Problem bei der Datenübertragung ist, daß in den Leitungen Übertragungsfehler entstehen können. In normalen Telefonleitungen ist die Bitfehlerwahrscheinlichkeit bei 10 . Die gebräuchlichste Einheit ist 1 bpe (bits per error). Telefon: 10 bpe. Um die Daten trotzdem korrekt übertragen zu können, verwendet man verschiedene Codes. Eine Maßzahl für die Güte eines Codes ist die Anzahl an Fehlern die er aushält (z.B.: even parity hält einen Fehler aus).
Das wichtigste Protokoll für die zweite OSI Schicht ist HDLC (High level Data Link Control
Die Übertragung wird so gestaltet, daß die Fehler gefunden, und ausgebessert werden können.
Bsp.: Für eine 1 wird 111, und für 0 wird 000 übertragen
die 0 kann sofort ausgebessert werden (diese Kodierung hält einen Fehler aus).
Das Problem dabei sind Fehlerbündel (error bundle), d.h. Fehler treten nicht alleine sondern in Bündeln auf, weil die Fehlerquelle nicht nur für ein Bit vorhanden war.
Mittels error detecting coding kann nur festgestellt werden, ob in den übertragenen Daten Fehler enthalten sind.
Even parity: Die Anzahl der Einsen in den Übertragungseinheiten ist gerade.
Bsp.: 1 Byte und Parity Bit
Das Selbe ist auch für eine ungerade Anzahl von Einsen möglich. Diese Art heißt dann 'odd parity'
Möglichkeiten, um statt einem Parity Bit eine Bitfolge zu verwenden.
CRC (cyclic redundancy check

VRC (vertical redundancy check
LRC (longitudinal redundancy check
Hier wird das Problem behandelt, wenn Fehler gefunden, aber nicht korrigiert werden können. Der Empfänger muß in einem solchen Fall dem Sender bekannt geben, wenn er einen Fehler entdeckt hat.
Eine Möglichkeit der Kontrolle ist, daß der Empfänger nach jedem Paket, das er korrigieren konnte ein Ack (Acknowledge) sendet. Der Sender weiß nun, daß das Paket korrekt angekommen ist, und daß er das nächste senden kann.

Der Sender müßte aber so immer eine gewisse Zeit warten, ob ein Ack kommt, wenn es nämlich ausbliebe müßte er erneut das Paket senden. Um die Wartezeit zu verkürzen sendet der Empfänger bei einem defektem Paket ein Nak (Negative Ack). Für diese Art der Kommunikation ist mindestens eine Halbduplexverbindung erforderlich.
Beim Sliding Window Protocol überträgt der Sender der Reihe nach Daten, ohne nach jedem Paket auf ein Ack oder Nak zu warten. Der Empfänger sendet jetzt je nachdem ob das Paket in Ordnung ist ein Ack oder Nak. Die Pakete, für die der Sender noch keine Ack's erhalten hat speichert er im Fenster. Eine typische Fenstergröße ist acht. Pakete mit Ack werden aus dem Fenster gelöscht. Erst wenn er für keine der acht Pakete im Fenster ein Ack bekommen hat, muß er das Senden unterbrechen.
Ein Fenster hat also folgende Form:
|
P73 |
P74 |
P75 |
P76 |
P77 |
P78 |
P79 |
P80 |
Unter Piggybacking versteht man, daß beide senden, und an die Pakete ihre Ack's für vorher gesendete Pakete anhängen.
Im dargestellten Netzwerk sind jetzt zwischen den einzelnen Knoten bereits Protokolle bezüglich der ersten beiden Schichten festgelegt worden. Das Problem das sich stellt ist, wie ein Knoten mit einem Paket umgeht, das nicht für ihn bestimmt ist (z.B.: Wohin leitet Lehner ein Paket für Geist weiter). Um das Problem zu beheben braucht jeder Knoten eine Routingtabelle, aus der er erfährt wohin er die Pakete weiterleiten muß. Z.B.:
|
Lehner |
|
|
Ziel |
Über |
|
Rösener |
Widder |
|
Bokor |
Bokor |
|
Geist |
0.5 Deutsch, 0.5 Widder |
|
|
|
Auf der linken Seite der Tabelle müssen alle Knoten stehen, auf der rechten können nur Nachbarn stehen. Wenn zwei gleichwertige Leitungen existieren, kann das wie in der dritten Zeile gelöst werden, und der Knoten kann selbst entscheiden welche Leitung er wählt.
Die Routingtabellen haben eine enorme Wichtigkeit, da einzelne Knoten bei schlechten Tabellen überlastet werden.
In großen Netzen (Internet) ist es nicht möglich für jeden Knoten einen Eintrag in jede Routingtabelle zu erstellen. Daher wird das hierarchische Routing eingesetzt, bei dem für ganze Regionen nur ein Weiterleitungsknoten steht:
|
Internetknoten |
|
|
Ziel |
Über |
|
Alle Knoten in Frankreich |
Knoten X |
|
Alle Knoten in Amerika |
Knoten Y |
|
|
|
Die Routingtabelle wird einmal festgelegt, und bleibt immer gleich. Das Problem hierbei ist, daß keine Rücksicht auf äußere Bedingungen (z.B.: Leitung unterbrochen, neuer Knoten hinzugefügt) genommen wird.
Isolated Routing:
Hier wird Auf Grund seiner "Erfahrung" (z.B.: Leistungsauslastung) des einzelnen Knoten von ihm die Routingtabelle erstellt. Diese wird regelmäßig nach einer gewissen Zeitspanne neu erstellt.
Centralised Routing:
Alle Tabellen werden im Routing Control Centre (RCC) erstellt. Der Nachteil ist die Überlastung der Nachbarknoten des RCC. Außerdem werden die Routingtabellen nicht aktualisiert wenn die Verbindungen zum RCC unterbrochen werden. In diesem Fall könnten neue Knoten nicht erfaßt werden.
Um Routingtabellen erstellen zu können müssen vorher diverse Einzelheiten festgelegt werden.
Hier wird festgelegt ob alle Pakete ankommen müssen, oder ob Pakete auch verloren gehen können.
Pakete müssen in der Reihenfolge ihrer Sendung ankommen. Ist dies nämlich gefordert darf es in der Routingtabelle keinen Eintrag wie "0.5 Deutsch, 0.5 Widder" geben.
Es muß auch festgelegt werden, ob ein Empfänger den Empfang von Paketen unterbrechen kann, ohne daß Pakete verloren gehen können.
Wie beim Versenden eines Briefes wird das Paket mit dem Empfänger versehen und versendet. Über den Weg zum Empfänger muß nichts bekannt sein. Ein solches Paket nennt man Datagramm.
Ahnlich dem Telefonnetz erhält jede Verbindung eine Nummer. Über die Nummer weiß das Netz sofort welchen Weg das Paket nehmen muß. Hier ist die Forderung der Einhaltung der Reihenfolge gewährleistet. Eine solche Verbindung nennt man Netzwerk.
Ein Deadlock ist dann gegeben, wenn ein Knoten keine neuen Pakete entgegennehmen kann, weil bereits alle seine Nachbarn den gleichen Zustand haben. Die Lösung hierfür ist das CHOKE-Paket, mit dem ein Knoten seinen Nachbarn mitteilt, daß sie langsamer senden sollen, weil er kurz vor einem Deadlock ist.
Ein Prozeß der Schicht 4 muß nicht nur die Adresse des anderen Rechners, sondern auch den Prozeß mit dem er kommunizieren will, bekanntgeben. Im Beispiel will ein Anwender in Wien durch die Eingabe einer Aktie deren Kurs ermitteln. Dies geschieht durch ein SQL Statement, das nach Los Angeles übertragen wird, wo die Datenbank ist. In LA führt ein Prozeß das Statement aus, und sendet das Ergebnis zurück:
Die Kommunikation zwischen den Rechnern ist in der nächsten Skizze dargestellt. Zu beachten ist, welche Daten zusätzlich zum SQL Statement übertragen werden müssen:
S3W muß zusätzlich zur Empfängeradresse auch den Absender übertragen, damit S3LA weiß, wohin sie die Daten zurücksenden muß.
Daraus ergibt sich für ein Schicht 4 Protokoll folgende funktionale Dekomposition:
Ein Broadcaststorm tritt dann auf, wenn ein Knoten eine Nachricht an alle anderen sendet. Jeder Knoten empfängt die Nachricht, und sendet sie laut Routingtabelle an seine Nachbarn weiter. Dadurch erhält jeder Knoten mehrmals die selbe Nachricht. Für dieses Problem gibt es mehrere Lösungen. Erhält ein Knoten das selbe Paket zum dritten Mal, leitet er es einfach nicht mehr weiter. Eine zweite Möglichkeit wäre, daß ein solches Paket im Knoten mit einer Kennung versehen wird. Wird dann wieder ein Paket mit Kennung empfangen wird es gelöscht.
Nicht nur auf den Datenleitungen, sondern auch innerhalb der Knoten kann es zu Übertragungsfehlern kommen. Um die korrekte Übertragung zu gewährleisten bildet man ein CRC für die Schicht 4. Aus den Daten werden dann mit den CRCs Pakete gemacht, die der Schicht 3 übergeben werden.
Connect - Request (Verbindungsaufbaupaket)
- ID Bits (zur Unterscheidung der Pakete)
- Länge (steht am Anfang)
- Qualitätsparameter
- end-to-end CRC
- kleine Datenmengen
Connect - Confirm
Daten
Ack
Experiential data (Eilpost)
EXP - Ack
Disconnect - Request
Steuerungspakete
Die OSI unterscheidet verschiedene Pakete, TCP hingegen kennt nur ein Paket mit verschiedenen ID Bits.
Die OSI regelt nur die Kommunikation zwischen zwei Rechner, aber nicht die innerhalb eines Rechners. Sie regelt z.B. nicht, ob S4 und S5 über einen Puffer oder mittels Datenbank miteinander kommunizieren. Solche Probleme, die mit der Kommunikation nichts zu tun haben, nennt man Local Matter. Diese sind aber für den Programmierer äußerst wichtig.
UNIX liefert für dieses Problem eine Transportinstanz mit. Der Programmierer muß nur mehr wissen, wie man damit kommuniziert. Über Betriebssysteme spricht man i.a. mittels Systembefehlen. Die Systembefehle für die Schicht 4 sind in BSD vorhanden.
BSD benützt zur Kommunikation Sockets (virtuelle Telefonstecker). Das Programm muß der Schicht 4 also sagen, daß sie ein Socket bilden soll.
Bsp.: Aktienkursermittlung
|
WIEN (Client) |
LOS ANGELES (Server) |
|
s=socket(); connect(s,"Aktienserver"); send("select "); e=receive(s); shutdown(s); |
sa=socket(); bind(sa,"Aktienserver"); listen(sa); while (1==1) |
Mittels bind erhält das Socket die Adresse, unter der Clients den Server erreichen können; listen macht das Socket empfangsbereit. Die Anweisung sb=accept(sa) verbindet sb mit Wien, und sa ist wieder für die Kommunikation mit anderen Clients frei.
Das Problem, das hier bearbeitet wird ist, wie die Verbindungen zeitmäßig verteilt werden, und wie im Falle eines auftretenden Fehlers wieder zum Beginn zurückgesetzt werden kann (Rollback).
Verschiedene Rechnersysteme stellen Zeichen oder Zahlen intern anders dar. Beispiele für Darstellungsarten sind Einser- oder Zweierkomplement, big oder little Endian. Es gibt aber auch verschiedene Zeichencodes wie ASCII, EBCDIC oder UNICODE. Es ist also erforderlich sich auf eine einheitliche Datendarstellung zu einigen. Weiters muß die Reihenfolge festgelegt werden. Mit einem Paket könnte zum Beispiel ein TAG gesendet werden, das die Datenstruktur des Paketes identifiziert.
Die OSI hat für Datenstrukturen die Beschreibungssprache ASN1 (Abstract Syntax Notation) entwickelt. Mittels ASN1 werden allgemein Datenstrukturen definiert. Diese können aus
String
Integer
Datum
bestehen. Mittels Set (ungeordnete Menge) und Sequenz (entsprechend Array in C) können auch kompliziertere Datenstrukturen aufgebaut werden. Um Datenstrukturen in Programme übernehmen zu können gibt es Compiler, die ASN1 in PASCAL oder C übersetzen.
Eine Transfersyntax ist ein Übersetzungsverfahren, um aus Datentypen binäre Zeichenfolgen zu machen.
Bei der Übertragung über Satelliten oder Kupferkabel ist die Abhörsicherheit nicht gewährleistet. Um die Daten abhörsicher zu machen, ist daher die Verschlüsselung erforderlich.
Die Kryptographie ist die Wissenschaft vom Erfinden neuer Verschlüsselungsverfahren. Die Kryptoanalyse ist die Lehre vom Entschlüsseln dieser Verfahren. Die Kryptologie umfaßt beide Gebiete.
Plaintext: Unverschlüsselter Text
Ciphertext: Verschlüsselter Text
Dabei werden Zeichen einfach durch andere Zeichen ersetzt. Z.B.:
A Error! Reference source not found. C
B Error! Reference source not found. X
C Error! Reference source not found. R
Dieser Code kann über die Häufigkeiten der Buchstaben in der Sprache entschlüsselt werden. (z.B.: Der häufigste Buchstabe in der deutschen Sprache ist das "E"). Allgemein ist festzustellen, daß längere verschlüsselte Texte leichter zu entschlüsseln sind, weil ihre Häufigkeiten representativer sind.
Porta schlägt für dieses Problem die Ersetzung von Buchstabenpaaren vor:
AF Error! Reference source not found. CX
BR Error! Reference source not found. FK
ZR Error! Reference source not found. _O
Aber auch Buchstabenpaare haben Häufigkeiten. Um diesem Problem entgehen zu können, müssen zuerst Wörter ersetzt werden:
ICH Error! Reference source not found. ROSE
WILL Error! Reference source not found. BERG
Ein Schlüssel wird festgelegt, und über den Text geschrieben. Dann zählt man im Zeichencode um die Ziffer aus dem Schlüssel weiter, und überträgt die neue Zeichenfolge. Bsp.: Schlüssel 1243:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
M |
O |
R |
G |
E |
N |
|
F |
R |
U |
E |
H |
|
A |
N |
G |
R |
I |
F |
F |
|
N |
Q |
V |
J |
F |
P |
D |
H |
S |
W |
I |
K |
A |
C |
R |
J |
S |
K |
J |
H |
Dieser Code ist zu knacken, wenn die Länge des Schlüssels bekannt ist, weil man dann weiß, daß jedes 4. Zeichen gleich verschlüsselt wurde, und dafür die Häufigkeiten ermittelt werden könnten. Selbst wenn die Schlüssellänge nicht bekannt wäre, könnte man sie solange durchprobieren, bis die Häufigkeiten mit denen der Sprache übereinstimmen.
a.) Sender und Empfänger treffen sich einmal und machen sich einen Code aus. Danach werden die Schlüssel, mit denen übertragen wird, mittels des Masterkey verschlüsselt übertragen.
b.) Puzzle Verfahren: Dieses wird angewandt, wenn sich Sender und Empfänger nie sehen.
Der Sender sendet tausende Pakete folgender Form:
![]()
Jedes dieser Pakete wird aber anders verschlüsselt. Der Empfänger sucht sich jetzt ein Paket aus, und versucht es zu entschlüsseln. Der Empfänger sendet dann die Nummer zurück, und der Schlüssel aus dem Paket dient als Masterkey.
Wurde von IBM entwickelt. Es gibt bereits fertige DES Chips zu kaufen. Für den Code war ein 128 Bit Schlüssel vorgesehen, die US Regierung bestand aber auf einem 64 Bit Schlüssel, da sie verhindern wollte, das es möglich ist, Nachrichten zu senden, die nicht entschlüsselt werden können.
Welcher Pfad muß angegeben werden, wenn ein Anwender aus Europa auf einen Rechner in den USA zugreifen will? Wie geht man mit nicht hierarchischen Dateisystemen um? Für diese Probleme stellen die OSI und TCP/IP Protokolle zur Verfügung. Übersetzer zwischen zwei Protokollen nennt man Gateway.
|
Problem |
OSI |
TCP/IP |
|
File Transfer |
FTAM (File Transfer and Access Management) |
FTP (File Transfer Protocol) |
|
|
X400 / MOTIS |
SMTP (Simple Mail Transfer Protocol) |
|
Terminalemulation |
VTS (Virtual Terminal Service) |
TELNET |
|
Verteilte Atomizität |
CCR (Commitment Concurrency Recovery) |
|
Das Socket des FTP ist auf allen Rechnern gleich, daher muß sich R1 nicht darum kümmern. Über die erste Verbindung wird ausgemacht, über welches Socket gesendet wird:
FTAM besteht aus acht Segmenten. Es ist aber zu kompliziert, um es vollständig zu implementieren.
SMTP stellt zum versenden von Emails einige Features zur Verfügung:
CC (Carbon Copy In ein CC Feld kann man alle eintragen, die den Brief bekommen sollen, besonders die, an die der Brief nicht adressiert ist.
BCC (Blind CC Der Empfänger kann zwar sehen, daß auch andere den Brief erhalten haben, weiß aber weder wer noch wieviele.
Der Übersetzer zwischen X400 und SMTP heißt Mail - Gateway.
Es gibt keine einheitliche Programmiersprache für Terminals. Das Buchungsprogramm wurde für T1 das Bestellungsprogramm für T2 geschrieben. Bei T1 löscht man mit Esc37 eine Zeile, und bei T2 mit Esc32.
Da die Befehle nicht zusammenpassen brauchen beide einen Übersetzer. Damit für jeden Terminal nur ein Übersetzungsprogramm geschrieben werden muß, wird alles in eine Universalsprache übersetzt. Diese Sprache heißt in TELNET NVT (Network Virtual Terminal). Hier sei das Löschen einer Zeile Esc34. T1 und T2 müssen nun alle ihre Anweisungen in NVT übersetzen.
Auch bei VTS ist wie bei TELNET ein virtueller Terminal vorhanden.
Ein Programm, das läuft, nennt man Prozeß (program in execution). In Netzwerken kommunizieren nicht Rechner, sondern Prozesse miteinander. Bei guter Netzwerksoftware entwirft man für jede Schicht ein eigenes Programm.
Innerhalb von Pauer funktioniert der Pakettransport folgendermaßen:
P2W liest Daten aus dem Puffer, prüft das CRC und schreibt das Ack in den Puffer. Ist das CRC in Ordnung, wird das Paket über den Puffer an die nächste Schicht weitergegeben. P2W ist aber auch dafür zuständig, daß Pakete für Widder aus dem Puffer gelesen, und weitergeleitet werden. Die Programme der zweiten Schicht (P2W, P2S, P2G) müssen nicht gleich sein, da für jede Verbindung ein anderes Protokoll festgelegt worden sein könnte.
P3 kann z.B. mittels polling (umfragen) umgesetzt werden. Der Reihe nach werden die Puffer gelesen. Sind Pakete in den Puffern, die nicht an Pauer adressiert sind, werden diese laut Routingtabelle weitergegeben. Die anderen werden über den Puffer an die vierte Schicht (P4) weitergeleitet.
Unter einer Protokollinstanz (protocolinstance) versteht man ein Programm, daß das festge-legte Protokoll verwirklicht. Eine Protokollinstanz ist nur für jeweils eine Schicht zuständig.
Haupt | Fügen Sie Referat | Kontakt | Impressum | Nutzungsbedingungen