Digital Audio
Was ist digital Audio?
Herkömmliche analoge Audiosignale sind Spannungsschwankungen,die analog an die Kopfhörer oder Laursprecher übertragen werden,und dann in Schallwellen umgewandelt werden.
Bei digital audio werden diese Spannungsschwankungen digital gespeichert.Der Audio-Output eines CD-Players oder Kassettenrekorders schwankt meißtens zwischen +/- 1Volt.Um von diesem analogen Signal ein digitales Abbild zu erhalten,wird diese Spannung sehr oft abgetastet = gesampelt,und die erhaltenen Informationen werden gespeichert.
Um die Qualität der so weit verbreiteten CD zu erhalten,muss das Audiosignal 44100 mal pro Sekumde mit einer Auflösung von 16 Bit = 65535 Abstufungen gesampelt werden.Die entstehende Datenmenge ist so ziemlich groß(1Minute 16 bit,44.1 Khz braucht ca 10 MB)
Der Vorteil von Digital Audio ist aber:Verlustfreies Kopieren,leichte Bearbeitung,und natürlich ein Rauschabstand,und damit auch ein Dynamikumfang von 90 db.
Um diese vorteilhaften digitalen Audiodaten zu komprimieren gibt es verschiedene Verfahren,wie zb Microsoft ADPCM oder Fraunhofer MPEG Layer 3.Näheres dazu später.
Digital Audio und Computer:
Der Computer ist das geeignetste Instrument um digitale Audioinformationen zu speichern und zu verarbeiten.
Unter dem weit verbreiteten Betriebssystem Windows gibt es folgende verlustfreie Audioformate,die alle PCM(Puls Code Modulation) genannt werden:Im Header der verschiedensten PCM Dateien sind sämtliche Daten über das File gespeichert:Samplingrate,Bitrate,Mono,Stereo,aber auch Informationen über die Quantisierung der Audiodaten(zb logarithmisch,oder linear:Bei einer logarithmischen Qantisierung wird der Dynamikbereich mehr dem menschlichem Hörempfinden angepasst,bei einer linearen quabtisierung ergibt sich ein besserer Klirrfaktor)und Informationen über das Schema der digitalisierten Audiodaten.Hier gibt es bei PCM:
Intel(LSB,MSB) Motorola (MSB,LSB) und bei acht Bit-Daten: A-Law-8bit und mu-Law-8bit.
Windows PCM waveform (.WAV)
Alle WAV formatieren halten sich and das RIFF (Resource Information File Format).Spezielle Informationen wie Copyright,aber auch die Informationen über Sampleraten und Bitraten sind im sogenannten Header der Datei gespeichert.Die Standard Windows PCM Dateien enthalten unkomprimierte Audiodaten.
Sound Blaster voice file format (.VOC)
Dies ist ein eigenes PCM-Audio-Format der Firma Creative für ihre alten Soundkarten Soundblaster und Soundblaster Pro.Es war für den betrieb mit dem soundblaster unter DOS gedacht.Dieses Format unterstützt nur 8bit; 44.1Khz Mono und 22 Khz Stereo.
Apple AIFF format (.AIF, .SND)
Das ist das Apple Standard WAV-File Format (vgl.WINDOWS PCM)
Sowie Windows PCM kann auch das Apple Format komprimierte Audiodaten enthalten.Näheres dazu später.
Amiga 8SVX (.IFF, .SVX) (*.*)
The Amiga 8SVX format is an 8-bit mono format, which can also be compressed to a 4-bit Fibonacci delta encoded format.
SampleVision format (.SMP)
Das SampleVision Format unterstützt nur 16bit/mono.Diese Format ist gedacht für Sampler.In der Datei selbst können Loop-Markierungspunkte gespeichert werden,die einem Sampler sagen,wie er das Audiomaterial behandeln soll.
ASCII Text format (.TXT)
Data can be read to or written from files in a standard text format, with each sample separated by a carriage return and channels separated by a tab character. Options allow data to be normalized between -1.0 and 1.0, or written out and read in raw sample values. An optional header can be placed before the data. If there is no header text, then the data is assumed to be 16-bit signed decimal integers.
Raw PCM Data (.PCM) (*.*)
Dieses Format ist das übergreifende Format aller PCM-audiodatein.In diesem Dateityp sind keine Header-Informationen gespeichert,deshalb wird beim Öffnen dieser Datei die Samplerate,sowie etwa die Quantisierung(MSM<>LSB) und die Anzahl der Kanäleabgedragt.Mit einem WAV-Editor der dieses Format unterszützt,kann man praktisch jedes unbekannte WAV-Format laden.Unbekannte Header-Informationen sind aber als kurzes Klicken oder Rauschen am Anfang der Datei hörbar.
Kodierung von Audiosignalen
Audio-Signale lassen sich zum Beispiel gegenüber Video-Signalen mit relativ geringer Bandbreite übertragen. Dennoch ist der Audio-Komponente der höchste Stellenwert zuzuschreiben, da der Mensch auf Störungen in der Ton-Wiedergabe
empfindlicher reagiert als auf ein fehlerhaftes Bild. Die Komprimierungsverfahren müssen das Signal im geforderten
Frequenzbereich nahezu fehlerfrei rekostruieren können.
ADPCM
Um den Bandbreitenbedarf des Audiosignals zu verringern, wird das Audiosignal bei der adaptive differential puls code
modulation (ADPCM) mit einem prädiktiven Verfahren kodiert. Abbildung zeigt das Blockschaltbild des
ADPCM-Coders. Das Audiosignal wird dabei zunächst wie bei PCM abgetastet und quantisiert (hier mit 8 kHz und 8
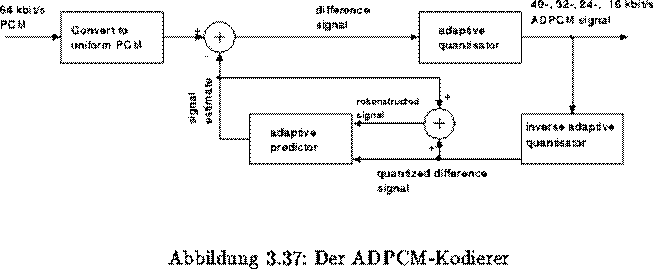
Bit/Sample). Das PCM-Signal wird dann im
PCM-Coder vom vorhergesagten Signal abgezogen und im adaptiven Quantisierer
mit 4 Bits kodiert. ADPCM arbeitet bei
Übertragungsraten von 40-, 32-, 24- oder 16 kbit/s.
Microsoft ADPCM waveform (.WAV)
Wie schon erwähnt können WAV Dateien (*.wav) auch kodierte/komprimierte Audiodaten enthalten.
Microsodt ADPCM komprimiert jeden Kanal einer Audiodatei nach dem oben beschriebenen Verfahren auf 4 bit.Jedes 4 Bit Sample wird beim Laden wieder auf 16 bit expandiert.
IMA/DVI ADPCM waveform (.WAV)
Dieser Standard komprimiert 16bit Wavdatein nach einem anderen,schnelleren Schema als Microsoft ADPCM.Es hat differente Klirrfaktorcharakteristiken.
CCITT mu-Law and A-Law waveforms (.WAV)
Diese Formate komprimieren 16bit Audio zu 8bit.Die Qualität liegt zwischen 8 und 16 bit,und ist jedenfalls besser als ADPCM. Thus, a-law and mu-law encoded waveforms have a higher s/n ratio than 8-bit PCM, but at the price of a little more distortion that the original 16-bit audio.
Dialogic ADPCM (.VOX)
Ein anderes 4bit ADPCM Format.Es wurde opiomiert für Sprachwiedergabe mit niedriger Samplerate.Kein File-Header.
ACM Waveform (.WAV)
Jedes Format,das bei Ihrem Computer unter Systemsteuerung>Multimedia>Audiokomprimierungscodecs installiert ist kann im ACM Format gespeichert und widergegeben werden.Zum Beispiel auch MPEG Layer3(siehe unten)
MPEG
MPEG-1-Audio:
MPEG-1 verwendet zur Kodierung des Audiosignals eine Technik, die das Signal zunächst in 32 Frequenzbänder teilt. Die einzelnen Spektralanteile werden dann in Abhängigkeit des enthaltenen Rauschens auf verschiedene Weise quantisiert. Zur Bestimmung des Rauschanteils wird ein ,,psychoakustisches Modell`` verwendet. Das quantisierte Signal wird in einem Code mit variabler Bitlänge kodiert und kann außerdem Huffman-entropiekodiert werden. Die Kodierung von Stereosignalen kann getrennt je Kanal oder im joint stereo-Modus gemeinsam vorgenommen werden. Im zuletzt genannten Fall werden die Übereinstimmungen auf beiden Kanälen berücksichtigt und ein höherer Kompressionsgrad erreicht.
Die MPEG-1-Audio definiert drei Coder/Decoder, die als Layer I-III bezeichnet werden. Die Encoder sind hierarchisch
kompatibel, so daß also der Decoder des Layer N in der Lage ist, Signale des Layer N und der darunter zu dekodieren. Die Komplexität der Coder und Decoder steigen mit der Ziffer des Layer.
Layer I beinhaltet das Aufsplitten des Audio-Signals in 32 Frequenzbänder, eine fixe Segmentierung der Datenblöcke und das psychoakustische Modell zur Bestimmung der Quantisierung. Layer 1 kann für Bitraten von 192 kbps pro
Audio-Kanal verwendet werden.
Layer II bietet eine zusätzliche Kodierung der Bit-Allokation, der Skalierungsfaktoren und der Samples. Layer II
ermöglicht die Bit-Rate von 128 kbps pro Kanal.
Layer III erhöht die Frequenzauflösung durch eine hybride Filterbank und verwendet einen anderen Quantisierer,
adaptive Segmentierung und Entropie-Kodierung der quantisierten Werte. Dieser Layer bietet Bit-Raten von 64 kbps
pro Audio-Kanal.
Fragen & Antworten zum ISO-MPEG Standard
F: Was ist eigentlich MPEG ?
A: MPEG ist die Moving Pictures Expert Group, was wohl ungefär mit Expertengruppe für bewegte
Bilder zu übersetzen ist (huaaaa *grin*). Diese Gruppe echt cleverer Leute arbeitet sehr eng mit der
International Standards Organization (ISO) und der International Electro-Technical Commission
(IEC) zusammen (diese Übersetzungen schenke ich mir !). Die MPE Group arbeitet an nichts anderem
als Codec-Standards für Audio/Video-Daten und hat natürlich auch eine eigene MPEG-Homepage.
F: Was bedeutet genau MPEG-1,-2 usw. ?
A: Die verschiedenen Standards entstanden nacheinander durch die gestiegenen Anforderungen. z.Zt.
sind 3 Standards fest definiert:
MPEG-1: Coding für Video-Daten und zugehörigen Ton bis zu einer Transferrate von 1.5 Mbit/s
MPEG-2: 'Generic' coding für A/V-Daten (was soll blos das 'generic' hier bedeuten ?)
[MPEG-3]: ursprünglich geplant für das HDTV; später in MPEG-2 integriert (wahrscheinlich wegen
des durchschlagenden Erfolgs von HDTV)
MPEG-4: Coding für Audio-Visuelle Objekte
F: Ist MPEG-3 und Layer-3 das Gleiche ?
A: NEIN !! Layer-3 ist die Bezeichnung für die Audio-Komponente der MPEG-Standards 1 und 2.
F: Wo kann man die genauen MPEG-Spezifikationen nachlesen ?
A: Einerseits bei der ISO-WWW-Seite, oder über E-Mail bei/in der DIN.
Wie funktioniert MP3?
Allgemein hat man zwei Möglichkeiten, um die erfordeliche Datenmenge zu reduzieren. Entweder man sampelt
weniger oft, oder sampelt mit einer geringeren Auflösung (als 16bit/sample). Um die Qualität zu erhalten, kann man an der Samplefrequenz nichts ändern. Das hat folgenden Grund: Das menschliche Ohr hört Frequenzen im Bereich von 20Hz bis 20kHz (Mittelwert); und nach der sogenannten Nyquist-Theorie muß die Sample-Frequenz doppelt so groß sein, wie die die höchste Frequenz, die man speichern will. Da diese Theorie allgemein anerkannt wird, läßt man die Samplefrequenz wie sie ist, und reduziert die Auflösung der Sampels.
Nun, da wir das wissen, müssen wir auf die Auflösung der Sampels genauer eingehen:
Der Grund, warum die Sampels 16bit groß sind, ist folgender: Man will eine ausreichend große
Signal-to-noise-Ratio (Signalrauschabstand, 's/n') erhalten. Das Rauschen, um welches es hier geht, entsteht
gezwungenermassen beim Digitalisieren der Sounddaten und wird im Fachjargon Quantisierungsrauschen
(quantisation noise) genannt. Für jedes Bit, welches man dem Sampel hinzufügt erhält man eine um 6dB
bessere s/n (+6dB entspricht etwa einer Verdopplung der Lautstärke, oder einer Vervierfachung der
Watt-Leistung). Eine Audio-CD hat eine s/n von etwa 90dB, was ausreicht, um dem menschlichen Ohr ein
rauschfreies Signal zu bieten.
Was passiert nun, wenn man die Grösse der Sampels auf 8bit reduziert ? Die Sounddaten werden mit einem
hörbaren Hintergrundrauschen (noise floor) unterlegt, den man in leisen Passagen deutlich hört. Aber eben nur
in leisen Passagen !! Laute Töne überlagern den noise floor, was man masking effect nennt, und genau das
ist der Schlüssel zur MPEG Audio Komprimierung. Effekte, wie dieser, gehören zu einer Wissenschaft, die sich
psyco-acustics nennt, und sich damit beschäftigt, wie das menschliche Gehirn und Gehöhr Töne verarbeiten.
Nun kommen wir endlich dazu, darauf einzugehen, wie die MPEG Audio Komprimierung diesen Effekt nutzt:
Am besten lässt sich das an einem Beispiel erklären. Nehmen wir mal an, wir haben zwei Töne, einen bei
1000Hz und den zweiten bei 1100Hz. Letzterer ist 18dB leiser, als der erste. Der Ton bei 1100Hz würde
vollkommen von dem bei 1000Hz überdeckt/maskiert werden, und somit unhörbar. Ein dritter Ton bei 2000Hz
mit -18dB relativ zum 1000Hz Ton wäre wieder hörbar, wenn man den Pegel dieses Tones auf -45dB absenkt,
würde er wieder maskiert werden. Eine direkte Folge davon ist, daß um den (lauten) 1000Hz Ton auch der
noise floor maskiert wird, deshalb können wir in diesem Bereich die Größe der Sampels reduzieren, was
weniger Daten/Sample entspricht, somit also eine Kompression ist.
Was sich hier mit drei Tönen noch recht einfach anhört, verlangt in einem komplexen Audio-Signal natürlich
einigen frequenzanalytischen und mathematischen Aufwand.
'Wie macht das nun ein MPEG Audio-coder ?' ist die nächste Frage, die man hier stellt. Er unterteilt das
Frequenzspektrum eines Audio-Signals (20Hz bis 20kHz) in 32 sog. Sub-Bands. Nehmen wir nun mal an, im
oberen Bereich von Sub-Band 8 liegt unser 1000Hz Ton mit einer Lautstärke von 60dB. Der Coder berechnet
nun den masking effect und stellt fest, daß der masking treshold (Maskierungs Schwellenwert, frei übersetzt)
für das komplette 8. Sub-Band 35dB unter diesem Ton liegt. Daraus resultiert eine benötigte S/N-Ratio von
60dB-35dB = 25dB, was einer Sampelgröße von 4 bit entspricht. Zusätzlich treten natürlich noch in allen neben
dem Sub-Band 8 liegenden Bändern Maskierungseffekte auf, die mit dem Abstand zum Ursprungsband
abnehmen. Diese Beeinflussung der Bänder untereinander, wird von den Coding-Routinen ebenfalls
berücksichtigt, was die Berechnungen noch komplexer macht.
Die Aufteilung der Sub-Bands ist ebenfalls eine wichtige Komponente der Kodierung. Waren in Layer II noch
alle 32 Sub-Bands gleich groß (625Hz), so sind sie in Layer III an die Eigenschaften des Ohres angepasst,
also kleiner in den empfindlicheren Bereichen, die (logischerweise) im Bereich der menschlichen Stimme
liegen (2 bis 4 kHz), was auch wieder komplexere Filter erfordert. In diesem Punkt hat man auf eine bereits
bestehende Filtertechnik zurückgegriffen, die DCT-Filter (Discrete Cosinus Transformation), auf die ich
hier nicht weiter eingehen möchte.
Der nächste, vom Coder berücksichtigte Effekt, ist das sogenannte Pre- & Postmasking. Findet in einem
Soundsignal ein großer Sprung in der Lautstärke statt (mind. 30dB), so tritt ein Premasking Effekt auf, der um
2-5 Millisekunden maskiert, sowie ein Postmasking Effekt, der bis zu 100ms abdecken kann. Man glaubt, daß
dieser Effekt daraus resultiert, daß das Gehirn eine gewisse Zeit braucht, um eine solche Dynamik
umzusetzen.
Der letzte Schritt vor der Formatierung der Daten, ist ein sog. Huffman-coding, welches folgendermaßen
arbeitet: Es ersetzt lange, häuftiger vorkommende Datenketten, durch kürzere, und speichert für den
Decodiervorgang diese Zuweisung einmal ab. Diese Art der Kodierung arbeitet verlustfrei, und ist u.a. auch
die Basis für Kompressionsalgorithmen für Computerdaten (wie ZIP, LHA, RAR usw.).
Alle diese masking effects und Kodierungen werden in einem iterativen Prozess berücksichtigt/berechnet,
welcher bei Layer II mit 23ms time-windows arbeitet, was bei sehr dynamikreichem Klangmaterial noch zu
Problemen führen kann. Im Layer III Format hat man sich dieses Problems angenommen, vermutlich durch eine
Verkleinerung der time-windows.
Übersicht der Komprimierungsfaktoren bei MPEG:
|
|
für Layer 1 (entspricht 384 kbps für ein stereo signal), |
|
|
für Layer 2 (entspricht 256..192 kbps für ein stereo signal), |
|
|
für Layer 3 (entspricht 128..112 kbps für ein stereo signal), |
Durch Auslassen des Stereo Effekts u/o Verringern der Bandbreite (Frequenzumfang des Signals) lassen sich noch höhere Kompressionsraten bei geringeren Bitraten erreichen. Die folgende Tabelle stellt bekannte Soundqualitäten den entsprechenden Layer-3 Kompressionsfaktoren gegenüber:
|
Klangqualität |
Bandbreite |
Modus |
Bitrate |
Kompressionsfaktor |
|
Telefon |
2.5 kHz |
mono |
8 kbps |
|
|
besser als Kurzwelle |
4.5 kHz |
mono |
16 kbps |
|
|
besser als Mittelwelle |
7.5 kHz |
mono |
32 kbps |
|
|
ähnlich wie UKW |
11 kHz |
stereo |
5664 kbps |
|
|
fast CD |
15 kHz |
stereo |
96 kbps |
|
|
CD |
>15 kHz |
stereo |
112..128kbps |
|
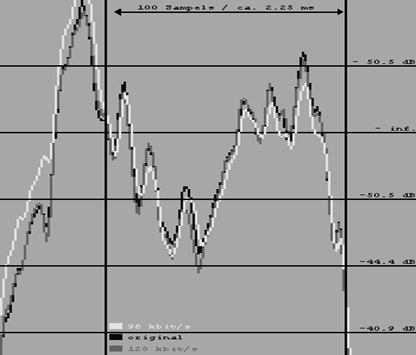
Viele Leute wollen erstmal nicht glauben, daß, trotz einer
prinzipbedingt verlustbehafteten Kompression, die Qualität erhalten
bleibt.Deshalb ist hier eine Grafik dargestellt:Es wurde von einer Audiocd ein
Stück digital ausgelesen.Das resultierende Wav-File wurde einmal mit 128kbit/s
und einmal mit 96kbit/s gepackt, und die beiden mp3-Files wieder in wav-Files
zurückgewandelt. Dann wurden alle drei Files in einen Wave-Editor geladen und
die Wellenformdarstellungen einer Passage auf das Sample genau
übereinandergelegt.
MP3 Encoder und Player:
Es ist nicht gleich,von welcher Softwarefirma der Encoder und/oder Player ist.Dies nicht etwa aus Gründen der Komfortabilität oder aufgrund einer attraktiven Oberfläche,sondern aufgrund der Firmenpolitik der Firma Fraunhofer.Die veröffentlichen ISO Definitionen über das Codierungs und Decodierungsverfahren sin unvollständig.So weicht die Klangqualität bei den unterschiedlichen Encodern ab.Bei besseren Encodern ist sogar zwischen zwei Schemen wählbar,nach denen das audiomaterial codiert wird.Auch ist nicht jeder Player diesbezüglich gleich.Ich kann einen hörbaren Unterschied zwischen WINAMP und einen MP3 Player direkt von der Firma Fraunhofer bei dem gleichen MP3 File erkennen.
Andere Audiokomprimierungen
Vor kurzem hat die Firma Microsoft mit einem eigenen Sytem gekontert.das angeblich eine Komprimierung
ohne hörbaren Unterschied von bis zu 20:1 ermöglicht.Sony will dieses Komprimierungsformat in eigene Audiogeräte
integrieren.
Weiters hat die Firma Fraunhofer MPEG Layer 4 in Arbeit.
FAZIT UND ZUSSAMMENFASSUNG:
MPEG - Kompression mit Köpfchen

Eines der wichtigsten Kompressionsverfahren für Audios und Videos ist MPEG. MPEG ist
und wird vom Frauenhofer Institut für Integrierte Schaltungen entwickelt und
weiterentwickelt. Grundlage des MPEG-Verfahrens ist die Biologie des Menschen. Der
Mensch selbst kann nicht alle Informationen wahrnehmen, zum Beispiel bemerkt er
bestimmte Farbänderungen, oder bestimmte Unterfrequenzen nicht. Somit ist es möglich,
nicht nur den Datenstrom an sich mit mathematischen Modellen zu komprimieren, sondern
ganz gezielt Informationen aus dem Datenstrom herauszuschneiden, die der Mensch bei der
Wiedergabe kaum wahrnimmt. Außerdem ist bekannt, daß man Bilder wesentlich effizienter
speichern kann, wenn man sich von Bild zu Bild nur die Unterschiede in den einzelnen
Bildern merkt. Im Falle von Audio kann man ebenfalls den Datenstrom auf diese Weise
komprimieren. Audios weisen nämlich meist auch die Eigenschaft auf, daß von Abstastung
zu Abtastung nur relativ selten starke Anderungen eintreten. Alles in allem setzte man alle
drei Kodierungsmöglichkeiten, differenzielle Kodierung (nur Wertänderungen abspeichern),
verlustbehaftete Kodierung (Daten können nicht 100%ig restauriert werden - Qualität wird
bedingt durch die Biologie jedoch nicht beeinträchtigt) und die Reduzierung der
Quellenentropie (Mathematisches Modell der Datenkompression) zu dem MPEG-1
Verfahren zusammen. Bereits mit MPEG 1 konnte man Komprimierungsraten von bis zu 1:3
(Bedarf beträgt nur etwa 1/3 des ursprünglichen Platzbedarfes) erreichen. Mit MPEG-2
verfeinerte man vor allem die Erkennung von biologischen Faktoren und damit die weitere
Entfernung von Informationen im digitalen Datenstrom, die der Mensch nicht wahrnehmen
kann. Mit MPEG-2 erreichte man nun immerhin schon Kompressionsraten bis zu 1:6. Erst
Mitte 1997 brachte die Frauenhofergesellschaft für Audios ein neues Verfahren heraus -
MPEG-3. Mit MPEG 3 kann man Audio ohne Qualitätsverlust bis auf 1/12 der
Orginalgröße schrumpfen lassen. Diese hohe Kompressionsrate erreicht man außerdem
durch eine verbesserte differentielle Kodierung. Im Gegensatz zur herkömmlichen
differentiellen Kodierung setzt man bei MPEG-3 auf folgendes Verfahren: Zu jedem
Zeitpunkt wird bereits die Nachfolgeinformation berechnet, wie sie eventuell aussehen
könnte. Im eigentlichen Datenstrom stehen nun nur noch die Informationen über die
Anderung zur Vorausberechnung. Da die Vorausberechnung in den meisten Fällen den
eigentlichen Werten sehr ähnelt, müssen nur noch wenige Informationen gespeichert werden,
was den Datenstrom erheblich reduziert.
Doch auch mit solchen Erfolgen sollte man nicht aufgeben. Biologen haben herausgefunden
das der 'Datenstrom' im Menschen zwischen Ohr und Gehirn nur wenige KByte/s beträgt.
Rein theoretisch sind somit noch weit bessere Kompressionsraten möglich, nur im Moment
weiß noch niemand, wie diese Informationen dermaßen stark komprimiert werden könnten.
Die Videokomprimierung nach MPEG3 wird sicherlich noch einige Zeit auf sich warten
lassen, da Videos eine wesentlich höhere Komplexität besitzten als Audios.
Haupt | Fügen Sie Referat | Kontakt | Impressum | Nutzungsbedingungen