- Datenbanken
- SQL
- ERD
- Access
RELATIONALE DATENBANKEN
RELATIONAL DATABASE
bedeutet eine Beziehung zwischen Tabellen.
![]()
![]()

Attributswert
Relation:
= Beziehung/Zusammenhang zwischen Objekten
Funktion:
= eindeutige Relation
Entität (Entity):
= wenn eine Zeile (=Datensatz) eindeutig identifizierbar ist. z.B.: Buch von Philipp
Entity Type:
= ein Überbegriff z.B.: Buch Rembold
HIERARCHISCHE DATENBANK
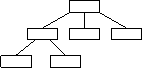
keine Verknüpfungen möglich (Information, Struktur streng hierarchisch)
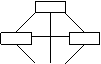
NETZWERKMODELL
![]()
Verknüpfung der einzelnen Objekte möglich, Ziel kann jedoch über verschiedene Verknüpfungen erreicht werden.
SQL
Structured (strukturierte
Query Abfrage
Language Sprache)
SQL = normierte Abfragesprache
ISQL (Interactiv SQL):
Abfrage wird eingegeben, Computer gibt das Ergebnis aus.
Nächste Abfrage wird eingegeben, usw.
ESQL (Embedded SQL):
hier wird programmiert embedded eingebettet
z.B.: im C-Programm wird eine SQL-Anweisung ausgeführt
SQL-Anweisungen unterteilt in 3 Gruppen:
) DML - data manipulating language (für Datensätze)
select selektieren
update ändern
delete löschen
insert einfügen
) DDL - data definition language (für Tabellen)
create erstellen
drop löschen (löscht Tabelle samt Inhalt)
alter ändern
) DCL - data control language (Benutzerrechte)
grant erteilen
revoke entziehen
select was (=Attribut, Attribut, )
from woher (=Tabellenname, Tab.name, )
where Bedingung
Bsp:
select * (* gibt den ganzen Datensatz aus)
from Schüler ( Tabelle Schüler)
where Alter>15 (es sollen nur die Schüler ausgegeben werden, die älter als 15 sind)
Operatoren
< > = <> (!=) <= >=
and or not in between
like is
Negationen: z.B.: not in, not between, is not,
Wichtig:
0 Ziffer
NULL nix
% beliebig viele Zeichen
_ genau ein Zeichen
Bsp: Name derjenigen, deren Gehalt zwischen 1000 und 2000 liegt.
select ename, sal
from emp
where sal between 1000 and 2000
Bsp: Welche Personen haben den Job CLERK, SALESMAN oder ANALYST.
select ename, job
from emp
where job in ('CLERK', 'SALESMAN', 'ANALYST')
Bsp: Alle Namen, die mit A anfangen.
select ename
from emp
where ename like 'A%'
Bsp: Namen derjenigen, die keine Provision bekommen.
select ename
from emp
where comm is NULL
ORDER BY
Bsp: Ausgabe der Angestelltennummer in der Abteilung 10, sortiert nach Namen.
1
select empno, ename
from emp
where deptno=10
order by ename (oder order by )
Nach order by können mehrere Kriterien angegeben werden, z.B.: order by No, Gericht
![]()
![]() No Gericht
No Gericht
1411 Spaghetti
1411 Spinat
ASC ascending (aufsteigend)
DESC descending (absteigend)
ANDERN VON 'ÜBERSCHRIFTEN'
select empno Mitarbeiternr, ename Name
from emp
![]() MITARBEITERNR NAME
MITARBEITERNR NAME
![]() 7396 SMITH
7396 SMITH
7499 ALLEN
Mitarbeiternr MITARBEITERNR
'Mitarbeiternr' Mitarbeiternr
AUSDRÜCKE UND FUNKTIONEN
![]() + - * / Grundrechnungsarten
+ - * / Grundrechnungsarten
|| Zusammenhängen von Zeichenfolgen
ABS (<numerischer Ausdr.>) Absolutbetrag
SIGN (<numerischer Ausdr.>) Vorzeichen
LENGTH (<String>) Länge
SUBSTR (<String>, von, Länge) Teilstring von einer Zeichenkette
NVL (<Ausdruck>, Ersatz) Konvertierung von NULL-Werten NVL NULL-value
Bsp: Alle Namen, die an der 3. Stelle ein A haben.
select ename ENAME
from emp BLAKE
where substr (ename, 3, 1)='A' CLARK
ADAMS
Bsp: Ausgabe vom Namen und Gehalt+Provision.
select ename, sal+nvl (comm, 0) ENAME SAL+NVL (COMM, 0) SAL+COMM
from emp SMITH 800
ALLEN 1900 1900
WARD 1750 1750
JONES 2975
MARTIN 2650 2650
. . .
. . .
. . .
NULL wird für diese Berechnung zu 0 konvertiert, um sie dann mit sal zu addieren.
Bsp: Zusammenhängen von Name und Beruf aus der Abteilung 30.
select ename || '-' || job 'NAME-BERUF' NAME-BERUF
from emp ALLEN-SALESMAN
where deptno=30 WARD-SALESMAN
.
.
.
GRUPPENFUNKTIONEN
I) SUM
Jahresgehalt pro Person?
select sal*12 SAL*12
from emp
.
Jahresgehalt aller.
select sum (sal*12) SUM (SAL*12)
from emp
II) MAX
max (<Ausdruck>)
III) MIN
min (<Ausdruck>)
IV) AVG
avg (<Ausdruck>)
Bei SUM, MAX, MIN und AVG werden NULL-Werte ignoriert.
V) COUNT
a) COUNT (*)
Zählt alle vorhandenen Datensätze.
select count (*) COUNT (*)
from emp
b) COUNT (<Ausdruck>)
Abzählen von Datensätzen ungleich NULL.
select count (mgr) COUNT (MGR)
from emp
c) COUNT (distinct <Ausdruck>)
select count (distinct job) COUNT (DISTINCT JOB)
from emp
GROUP BY
Bsp: Durchschnittsgehalt pro Filiale.
select distinct deptno DISTINCT DEPTNO
from emp
select avg (sal) AVG (SAL)
from emp
where deptno=10
select avg (sal)
from emp
where deptno=20
.
.
.
einfacher:
select deptno, avg (sal) DEPTNO AVG (SAL)
from emp
group by deptno
HAVING
Nach der group by - Klausel kann kein where benutzt werden. SQL bietet dafür den Filter having an.
Having definiert eine Bedingung, welche sich auf das Ergebnis der Gruppierung bezieht. Es ist somit möglich, je Gruppe die Entscheidung zu treffen, ob diese in die Ausgabe mit aufgenommen werden soll oder nicht.
In having können Gruppenfunktionen (min, max, ) benutzt werden, die in where nicht zulässig sind.
JOINS
= Abfrage mehrerer Tabellen
EMP DEPT
empno, ename, deptno, ename, deptno,
![]()
select
from emp, dept KARTESISCHES PRODUKT wird gebildet (= 14*4 Datensätze)
![]() select emp.deptno
select emp.deptno
from
Tabellenname (von der das Attribut angegeben wird)
INNER JOIN
= zur Vermeidung des kartesischen Produkts
select
from emp, dept
where emp.deptno = dept.deptno in diesem Beispiel wären es nur noch 14 Datensätze
OUTER JOIN
hier werden Datensätze miteinbezogen, die in einer anderen Tabelle nicht vorkommen (wird selten benutzt).
select
from emp, dept
where emp.deptno (+) = dept.deptno Filiale 40 hat in der Tabelle EMP keinen entsprechenden Datensatz.
Durch das Anführen von (+), werden bei dieser Tabelle
Datensätze mit dem Wert NULL generiert.
Die Benennung des Joins erfolgt dadurch, ob links (LEFT OUTER JOIN) oder rechts (RIGHT OUTER JOIN)
NULL-Werte angefügt werden (emp.deptno = dept.deptno LOJ / dept.deptno = emp.deptno ROJ)
EQUI JOIN
= die Verknüpfung innerhalb einer Tabelle
select
from emp E1, emp E2 E1 und E2 = Synonyme
where E1.deptno = E2.deptno Verknüpfung mit sich selbst (um z.B. ein Liste aller Mitarbeiter
und deren Vorgesetzten auszugeben)
SUBSELECTS
man darf selects miteinander verschachteln
select ename, job, deptno
from emp
where job = (select job
from emp
where ename = 'JONES')
Ein SUBSELECT kann auch nach group by verwendet werden ( having avg (sal) > (select ) )
Operatoren die nur ein Ergebnis zurückliefern:
= > < >= <= <> (!=)
Operatoren, bei denen ein subselect mehrere Ergebniszeilen zurückliefert:
any all in = any != all > any < any > all
( in ) ( not in ) ( > min ) ( < max ) ( > max )
VIEW
= Ansicht, Lupe od. Fenster einer oder mehrerer Tabellen, für vollständige bzw. Teil-Ansichten
In der VIEW sind keine Datensätze; sie besteht nur aus einem select - Statement. Werden in der/den zugehörigen
Tabelle(n) Daten verändert, so ändert sich auch die VIEW. Soll die Originaltabelle geschützt werden oder
soll verhindert werden Daten zu Manipulieren und zu Andern, so wird eine VIEW angelegt.
Vorteil einer View ist, daß man wichtige Daten die öfters benötigt werden zusmmenfassen kann. Sollen einige Daten für andere Benutzer gesperrt bleiben (z.B.: Gehaltsdaten), so kann dies mittels eines selects erfolgen.
Tabelle A Tabelle B View Z
|
A1 |
A2 |
A3 |
A4 |
|
|
|
|
B1 |
B2 |
B3 |
B4 |
B5 |
|
|
|
A1 |
B2 |
B4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
create view Z as
select A1, B2, B4
from A, B
where A4=B5
order by darf nicht bei der Erstellung einer View vorkommen.
Wird im select - Statement ein Berechnungsausdruck verwendet, so muß als Attribut ein Name gewählt werden
create view X (maxsal, ) as select max(sal), from ].
Ansonst wird mit einer View wie mit einer Tabelle gearbeitet: select *
from Z
löschen einer View: drop view Z
TABLE
= Tabelle, in der die Daten gespeichert sind
erstellen einer Tabelle: create table name
löschen einer Tabelle: drop table name
Bsp: Erstellen einer Tabelle mit verschiedenen Attributen
create table allgemein
(MITNR number (4) not null, NAME char (12), DATUM date, GEHALT number (7,2))
Als Attribute gelten:
char (n) Zeichenfolge mit max. Länge n
number (n,d) num. Wert mit gesamt n Stellen und d Nachkommastellen
date Datum
not null bedeutet, daß in dem Feld immer ein Wert stehen muß der ungleich null ist.
Soll eine vorhandene Tabelle erweitert werden, so muß alter verwendet werden:
alter table allgemein
add (PROZENT number (6,2))
Unsere Tabelle sieht jetzt so aus:
ALLGEMEIN
|
MITNR |
NAME |
DATUM |
GEHALT |
PROZENT |
|
|
|
|
|
|
Es gibt verschiedene Möglichkeiten, um Datensätze in einer Tabelle anzulegen:
I) insert into
insert into allgemein
values (12, 'JAMES', '24-APR-93', 1234.76, 3.25)
Eintragen in bestimmte Felder: insert into allgemein (MITNR, NAME, GEHALT)
ALLGEMEIN
|
MITNR |
NAME |
DATUM |
GEHALT |
PROZENT |
|
|
JAMES |
|
|
|
Bei insert into werden einzelne Datensätze angelegt.
II) insert select
insert into allgemein (MITNR, NAME, DATUM, GEHALT)
select empno, ename, hiredate, sal
from emp
Bei insert select werden Datensätze von vorhandenen Tabellen übernommen.
Zu beachten ist die richtige Reihenfolge der Attribute und die Übereinstimmung des Datentyps.
Es können nicht nur neue Datensätze angelegt werden, sondern auch vorhandene nachträglich verändert werden:
update allgemein
set gehalt = 5000
where prozent = 3.25
Wie bei insert select kann auch bei update subselects verwendet werden.
Hier besteht die Möglichkeit, daß nach set ein subselect folgt, um einen variablen Wert einzufügen.
SYNONYME
Synonyme werden verwendet, um eigene Tabellen mit gekürztem Tabellennamen darzustellen, oder
um sie anderen Benutzern zugänglich zu machen (inklusive Berechtigung).
erstellen eines Synonyms: create (public) synonym name public .. allgemein zugänglich
for username.tabellenname
löschen eines Synonyms: drop synonym name
INDEX
In einer SQL - Datenbank werden die einzelnen Datensätze in undefinierter Reihenfolge gespeichert.
Wird ein Datensatz gesucht, so muß die Tabelle sequentiell durchsucht werden. Bei größeren u/o miteinander
verknüpften Tabellen können dadurch längere Wartezeiten entstehen.
Ein Nachteil des Verfahrens ist der Mehraufwand, da neben der Tabelle auch die Indexdatei gewartet werden muß.
erstellen eines Indexes: create (unique) index name on tablename
(columnname, asc/desc )
löschen eines Indexes: drop index name
TRANSAKTIONEN
In (ORACLE - ) SQL werden Anderungen temporär ausgeführt. Dies hat den Vorteil, daß z.B. bei einem Stromausfall die Hauptdatenbank nicht verändert wird. Will man nach einer Transaktion auf die Hauptdatenbank
schreiben, so muß COMMIT eingegeben werden. Ist man mit den Anderungen nicht zufrieden, so muß
ROLLBACK eingegeben werden. Dieser Befehl erlaubt es, alle Anderungen bis zum letzten COMMIT zurückzunehmen.
Bis zu dieser Seite ist der Lernstoff im Skript Einführung in SQL v3.0 nachzulesen.
ENTITY RELATIONSHIP DIAGRAMM
ERD
= die graphische Darstellung der Beziehungen zwischen den Tabellen
Die Beziehungen werden im Uhrzeigersinn betrachtet.
Bsp:

I) Lehrer unterrichtet min. 1 und max. mehrere Schüler
II) Schüler wird unterrichtet von min. 1 und max. mehreren Lehrern
Bezeichnung immer singular: der Lehrer, der Schüler,
ENTITIES
Beziehungen zwischen Entities:
1 : 1 Schule - Direktor
Ehemann - Ehefrau
1 : m Direktor - Lehrer
Mutter - Kind
m : n Lehrer - Schüler
|
|
I) FUNDAMENTALE ENTITAT
Die Entität hat für sich betrachtet eine Bedeutung, ohne Abhängigkeit von einer anderen Entität.
|
|
II) ATTRIBUTIVE ENTITAT
Sie ergänzt eine fundamentale Entität.
|
|
III) ASSOZIATIVE ENTITAT
Sie beschreibt die Beziehung zwischen den Entitäten (m : n Beziehungen auflösen).
Bsp:

___ Primary Key
m : n Beziehungen will man im ERD nicht haben assoziative Entität
Regel:
-) m : n Beziehungen müssen im ERD aufgelöst werden
|
|
-) Relationen haben immer einen Namen
SCHLÜSSEL (key)
I) PRIMAR SCHLÜSSEL (primary key)
ist ein Schlüssel (Attribut), der den Datensatz eindeutig identifiziert
'not null' ist nicht erlaubt/möglich
II) SEKUNDAR SCHLÜSSEL (secondary key)
muß den Datensatz nicht mehr eindeutig identifizieren, hilft ihn aber schneller zu finden
III) SCHLÜSSELKANDITAT (kanditatkey)
wenn mehrere Attribute als Primärschlüssel benutzt werden können
Mitarbeiter Projekt Projektbeteiligung
|
MNr |
MName |
MAdr |
|
|
PNr |
PName |
|
|
|
MNr |
PNr |
Dauer |
|
|
SCRO PIFF |
Ungarg. 69 Ungarg. 69 |
|
|
|
Internet ISDN |
|
|
|
|
|
|
Regel:
-) primary keys müssen gesucht werden (und werden im ERD immer unterstrichen)
NORMALISIERUNG
= wie ERD, jedoch ohne graphische Darstellung
Die Aufgabe der Normalisierung ist es, Denundanzen (Datenüberfluß) und die damit verbundenen Probleme
aus der Datenbank fernzuhalten.
|
MNr |
MName |
MAdr |
Ort |
PBez |
|
|
|
PIFF |
|
WIEN |
Internet |
Redundanz, wenn sich z.B. die Madr ändert |
|
|
PIFF |
|
WIEN |
ISDN |
|
1. Aussage: Ein Mitarbeiter hat einen Namen
Ein Mitarbeiter hat einen Wohnort
Ein Mitarbeiter ist in einer Abteilung tätig
Ein Mitarbeiter arbeitet an mehreren Produkten
. Ein Mitarbeiter arbeitet eine bestimmte Zeit am Produkt
. Jede Abteilung trägt eine eigene Bezeichnung
. Jedes Produkt trägt eine eigene Bezeichnung
In einer Abteilung sind mehrere Mitarbeiter tätig
An einem Produkt arbeiten mehrere Mitarbeiter
Jeder Mitarbeiter hat eine Mitarbeiternummer
Jede Abteilung hat eine Abteilungsnummer
12. Aussage: Jedes Produkt hat eine Produktnummer
Tabelle:
|
MName |
Wohnort |
Abt. |
Prodt. |
Zeit |
MNr |
PNr |
Abtnr |
|
Motti |
Zürich |
Physik |
A, B |
|
|
|
|
|
|
|
|
|
|
|
|
|
Regel:
1. Normalform (1. NF)
Kreuzungspunkt zwischen Spalten und Zeile darf max. 1 Wert aufweisen.
Eine Relation ist in 1. NF, wenn jedes Attribut der Relation vom Schlüssel funktional abhängig ist.
D.h. jedes Attribut hat zu jeden Schlüsselwert nur einen bestimmten Attributswert, man sagt auch:
jedes Attribut ist auch atomar (= elementar).
Es kann zu jedem Schlüsselwert genau ein Attributswert genannt werden (kann auch leer sein).
Attribute
Relation R (A1, A2, A3, ) = Zuordnung
1. NF R (S1, S2, A1, A2, A3, )
![]()
Maßnahmen für die 1. NF
Schlüsselkanditat finden; bei Kreuzungspunkt nur einen Eintrag
Haupt | Fügen Sie Referat | Kontakt | Impressum | Nutzungsbedingungen